�u�x�L���v�����u�X���[�����[���h�v��
�P�A�ΐ��ڐ��Ő��E������@���@(��Ԃ̃X�P�[��)
T�F�O��A�u�ΐ��O���t�Ǝw���@���v�ŁA�ΐ��ڐ����w�ˁB���x�́A���̃X�P�[�������R�E�ɓ��Ă͂߂Ă݂悤�B
S�F�ΐ��ڐ��Ŏ��R���v�邱�Ƃ��ł���́H
T�F���ʂ̖ڐ��Ōv������ʔ������Ƃ��킩���Ă����B�܂��́A���낢��Ȃ��̂�ڐ��ɓ��Ă͂߂Ă݂悤�B
�@������(�זE)�@�@�@�@�����@�@�@�@�@�l�ԁ@�@�@�@�~�@�@�@�@�@�Љ�E���Ԍn�@�嗤�@���@�@
�@�@�@�@10-4�@ �@10-3�@�@10-2�@�@10-1�@�@100�@�@101�@�@�@102�@�@103�@�@�@104�@�@105�@(��)
�@�@�@��������������������������������������������������������������
S�F�זE���猎�܂ŁA�����ڐ��ɍڂ��ł��ˁB
S�F���̖ڐ��������Ƒ傫������ƁA�ǂ��Ȃ�́H
�K�w�@�@�@�@�@�@�f���q�@�@�@���q�@���q�@�@�����@�@�@�@�@�f���@�@�@�P���@�@�@�@�@�@�@�@��́@�A�\��
�����@�@�@�@�@�@�@���q�j�@���f�@���q�@�������M���ށ@�n���@�@���z�@�@�@�@�@���c�@�@
��́@�@�@�F��
�@�@�@�@10-20�@ �@10-15�@ �@�@10-10�@�@�@10-5�@�@�@ 100�@�@�@�@105�@�@�@�@1010�@�@�@1015�@�@�@�@1020�@�@�@ 1025�@(��)
�@�@�@��������������������������������������������������������������������������������
�@���@�@�@�@�ʎq�͊w�@�@�@�@�@�@�@�@�M�͊w�@�@�@�j���[�g���͊w�@�@�@�@��ʑ��ΐ����_
�@�@�@�ア���ݍ�p�@�@�@�@�@�d���C�́@�@�@�@�@�@�@�@�@�@�@�@�@�@�d��
�@�@�@�������ݍ�p
T�F���̉��ɏ����Ă���̂́A���Ă͂܂镨���@���ȂB
S�F�u�]�E�̎��ԃl�Y�~�̎��ԁv�̏����Ȑ����́A�M�͊w�̖@���̒��Ő����Ă���Ƃ����̂ł��ˁB
S�F�ʎq�͊w�Ƃ���ʑ��ΐ����_�Ȃ�āA����ȁ[���B
S�F��������Č���ƁA���̐��E�͈ĊO�����Ȃ��B
T�F�����ȂB���������m���Ă���̂́A���͈̔͂����ȂB
S�F����́A�ΐ��ڐ��Ō��Ă��邩��ł���B
S�F���������A���Ԃ̃X�P�[���������悤�ɍl�����Ȃ��́B
T�F�����ȂB�����Ŏ��Ԃ̃X�P�[������낤�Ǝv���Ďn�߂����ǁA���̋�Ԃ̃X�P�[���͂��̂܂��Ԃ̃X�P�[���ɂ��Ȃ邱�ƂɋC�������B
S�F���Ԃɂ��A�ŏ��ƍő傪����Ƃ������ƂȂ�ł����H
T�F�l�Ԃ̐S���͂P00�b�łP���B�n�c�J�l�Y�~�͂P�O-1�A�~�͖�P�O1�B�ŏ��̓v�����N���ԂP�O-43�b�ŁA�ő�͉F���̔N��P�R�U���N���P�O18�b�B���̖ڐ��́A�����ߋ��ʼnE������(����)�̂悤���B
S�F��������Č���ƁA���R�ɂ͒i�K������悤�ȋC������ȁB
T�F�����ȂB���R�ɂ͊K�w������A���Ă͂܂镨���@�����Ⴄ�B�����ǁA�K�w���z�����@���͂Ȃ��̂��낤���B
S�F�X�P�[��������Ă��A���Ă͂܂�@��������̂ł͂Ȃ����Ƃ������ƁH
S�F���L�̉Q�́A�䕗�ɂ����������A���_�ɂ���������B�i�͂܂���̐��w�j
�Q�A�ΐ��ڐ��ŊW������@���@(�W�b�v�̖@���j
T�F�ȑO�A�u�G�h�K�[�E�A�����E�|�[�v�̂Ƃ���ŁA���ʂ̉p��̒P��ł悭�g������̂̏o�Ă��銄���ɂ��āA�u�W�b�v�̖@���v�����藧���Ă���Ƃ������Ƃ�������ˁB1�ʂ�THE�A�Q�ʂ�OF�A�R�ʂ�AND�ł��̕p�x�́A���ʂɋt��Ⴗ��Ƃ������́B���̕��z�̓t���N�^�����z�ɂȂ��Ă���B���i�ΐ��O���t�j�u�W�b�v�̖@���v�փ����N
�\�ɂ���ƁA
�@�@�@�@�@�o�����ʁb�@�P�@�@�@�Q�@�@�@�R�@�@�@�S�@�c
�@�@�@�@�@�o���p�x�b�@0.1�@0.05�@0.033�@0.025�@
S�F�ΐ��O���t�̌X����-�P�Ƃ������Ƃ́A�w����-�P�ŁA���ɂ���ƁA����0.1��-1���B�i���ߕ��́u�ΐ��O���t�v�̃y�[�W�j
T�F������������a��-1�ɂȂ�W���A�u�W�b�v�̖@���v�Ƃ����B
S�F���ɂ��A���̖@���ɓ��Ă͂܂���̂������ł����B
T�F�ł́A���́u�͂܂���̃T�C�g�̊e�y�[�W�v�̃A�N�Z�X�����A�ΐ��O���t�ɂ��Ă݂悤�B
| ���� |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
| �� |
24419 |
11153 |
7105 |
5687 |
5124 |
4847 |
4625 |
3849 |
3845 |
3755 |
3646 |
3160 |
S�F�P�ʂ̓_���g�c�ł��ˁB����A�ǂ̃y�[�W�ł����H
T�F�u�A���L���f�X�͋��̑̐ς��ǂ�����ċ��߂��̂��v�̃y�[�W�ł���B
S�F���ϓI�ɃA�N�Z�X��������킯�łȂȂ���ł��ˁB
T�F����Ⴛ���ł���B�l�C�̂���y�[�W�Ƃ����łȂ��y�[�W�������āA���̊����͂����������܂��Ă��āA���ꂪ�������v�����Ƃ�����̊����ɂȂ�͓̂��R�ł���B�����A���̖����̊������ǂ����܂�̂��͕s�v�c�ł��ˁB
S�F�Q�ʂ́A�P�ʂ̂��������������炢���B�G�N�Z�������āA�O���t�����A�ΐ��ڐ��ɂ��Ă݂悤�B
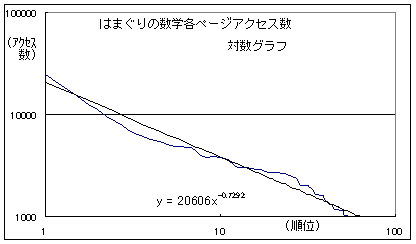
S�F���̒����͋ߎ��l�ł����H
T�F�����ł��B�G�N�Z���ł͎����I�ɕ`���Ă���܂�[�ߎ��Ȑ��̒lj���]�B�����āA���̌X����-0.7292�B
S�F�����ł͂Ȃ��悤�ȁc�B�ł��A�߂����ȁB
S�F�X����-1�ł͂Ȃ��ł���B����20606�^��0.73�B
T�F�����ł��ˁB-0.73��-1�ɋ߂��Ƃ������邯�ǁA�Ⴄ�ˁB
S�F��������a��-1�ł͂Ȃ��A����a��-0.73������A�u�W�b�v�̖@���v�Ƃ͈Ⴄ���ǁA����������Ɩ@������B
T�F������A�s�s�ʐl���Ȃ�A�C���^�[�l�b�g�ł����ɒ��ׂ邱�Ƃ��ł��邩�����Ă݂悤�B�܂��A���E�e���̓s�s�ʐl���ׂĂ����B
S�F������������ˁB�Ȃ��Ȃ�������Ȃ��Ȃ�����B���A�u���{�̓s�s�ʐl���̃f�[�^�v���������B
| ���� |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
| �l�� |
8083980 |
3466875 |
2490172 |
2117094 |
1837901 |
1483670 |
1386372 |
1315007 |
1258605 |
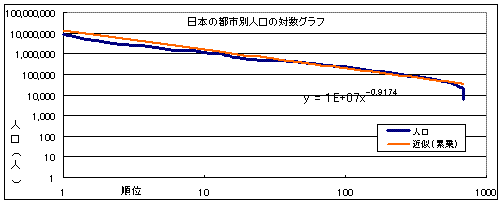
S�F����́A���Ȃ�A�����ɋ߂��ˁB
S�F�X���́|0.9�ł��ˁB�W�b�v�̖@���ł͂Ȃ�����ǁA����10000000�^��0.9�Ƃ����@�������藧�B
S�F����A�����s��1200���l��������Ȃ��H
T�F����1�ʂ̐l���́A���ʋ�̐l�������݂�������B�s�s������ˁB
S�F�ǂ����āA�����ɕ��Ԃ낤�H�s�v�c���ȁB�������̃y�[�W�̃A�N�Z�X���Ɠ������Ƃ��N�����Ă���̂��ȁB
S�F���łɍ��ʂ̓s�s�ʐl�������ׂĂ݂悤��B
�@�@�@���
S�F�A�����J��V�A�̃f�[�^������������B
S�F���ɂ���ČX�����Ⴄ�B�l���̑������قnjX�����������Ȃ�悤�ȁB
S�F������������A�l���̑����ƌX���͉����W�����邩������Ȃ��B
S�F�������Ƃ�����A���������������B���̍������ׂĂ݂悤�B
�R�A�u�x�L�@���v�Ɓu�p���[�g�̖@���v
T�F���̂悤�ɁA���R�E�ɂ͑ΐ��O���t�ŕ\���ƁA�����ɂȂ�W���ƂĂ������B�Ⴆ�A�n�k�̃G�l���M�[�ƉB�K���X�̔j�Ђ̑傫���ƌ��B���̃N���[�^�[�̃T�C�Y�Ɛ��A���f���̃T�C�Y�Ɛ��ȂǁB
S�F������u�W�b�v�̖@���v�Ȃ�ł����B
T�F�u�W�b�v�̖@���v�́A�X����-�P�̏ꍇ�����B���̌X����-0.9��-�Q��-�R�ɂȂ�ꍇ�̕��������B
S�F�}�C�i�X�����甽���ł��ˁB�O���t�͍��֍s�������قǏオ��B
T�F���̂悤�ɁA��������n�i���̓}�C�i�X�̗L�����j�ŕ\�����W���A�u�x�L�@���v�Ƃ����B���̊W�́A���R�̃X�P�[���Ɍ��炸���낢��ȂƂ���ŕ\���B
S�F�ΐ��ڐ��ł͂Ȃ��āA���ʂ̖ڐ��̃O���t������ƁA1�ʂ����|�I�ɑ�������100�ʈȉ��͂قƂ�Ǐ��Ȃ��Ƃ������Ƃł��ˁB
T�F�����ȂB���̊W����A�ʔ������Ƃ��o�Ă���B����́A�u�W�O�Q�O�̖@���v�Ƃ����B�C�^���A�̌o�ϊw�҃p���[�g�����������������z�̌o�����ŁA�S�̂�2�����x�̍��z�����҂��Љ�S�̂̏����̖�8�����߂�C�Ƃ����@���B
S�F������������ȋC������ȁB�������͂߂��Ⴍ�������������B
S�F�z���g���Ȃ��B
T�F���̐l���̏ꍇ�A���20���̓s�s���S�̂̐l����80���������Ă��邱�Ƃ������B
S�F�{���ɂ����Ȃ邩�A�G�N�Z���Ōv�Z���Ă݂悤�B
�S���łU�X�P�s�B��ʂQ�O�p�[�Z���g��138�ʂ܂ŁB���̍��v��66,404,426�l������A�S�̂̍��v�l���ł��ƁA��������65�����B
S�F��̃O���t������ƁA�p���[�g�̖@�������Ă͂܂肻�������ǁA�W�O���������Ă��Ȃ���B
S�F�������Ƃ͑������ǁA����ς�A���̖@���͂���������Ƃ͌���Ȃ���B
T�F�Ƃ��낪�A�p���[�g�̖@���͂��낢��ȂƂ���Ŏg�p����Ă���B
�Ⴆ�A
�u�S���i��20����80���̔�������A�S�ڋq��20�����S�̔����80�����߂�A100�̋a�̓��A�悭�����̂�2�������A�ŋ���[�߂���20�����ŋ����z��80���S���Ă���E�E�E�v
�ȂǁB�����āA�ǂ��g���Ă��邩�Ƃ����ƁA
�u���i�̕i���Ǘ��̕���ŏd�_�I�ɉ��ǂ��ׂ����̂��d�v�Ȃ��̂��珇�Ԃ�10���ڂ������ꍇ�A�܂��A���̍ŏ�ʂ�2�̍��ڂ��������ǂ���B����ƁA�S�̂�80�������ǂ����̂Ɠ����̌��ʂ����҂ł���B�v
�Ƃ����悤�ɁB
S�F�O�Ɂu�}���z�[���̂ӂ��͂Ȃ��ۂ��H�v�ɁA�u�����A���v�Ɓu�ӂ��A���v�̘b����������B
�w�A���̑����������ʁA�u���̊O�ɃG�T���̂�ɍs���v�u���⏗���A�����Ȃ߂Ă��ꂢ�ɂ���v�u���݂��̂Ă�v�Ȃǂ̎d�����قƂ�ǂ��Ȃ��A�����A�ǂ̃R���j�[�ɂ���Q�������B
�����̗ǂ��U�C����菜���ƁA���Ɏd���M�S�ȑw�̘J���ʂ�����������A�����Ȃ��w�͂���ς蓭���Ȃ������B�t�Ɏd�������Ȃ��U�C����������ƁA�悭�d�������Ă������C�̘J���ʂ͎�A�������Ƃ����B�x
����́A�j���[�X�ɏo�Ă�������A�����ł���B
S�F�A���͂Q�����u�ӂ��ҁv�ȂB�W���́u�����ҁv�B�p���[�g�̖@���̋t���B
S�F��������ƁA��Ђ̂Q�O���̐l���A��Ђ̂W�O���̎��������Ă���Ƃ������b�����������ˁB
T�F���������Ƃ��́A�G�N�Z���ŃԂ��P����100�܂ŁA��1�`��2�̒l���v�Z���Ċm���߂�B�ĊO�ȒP����B
S�F������-1�ł́A���20�����S�̂�69���B������-1.2��������A79.3���ɂȂ�����B
S�F�Ԃ̎w����-1.2����������������A�p���[�g�̖@���͐��藧�Ƃ��������ƂȂ́H
T�F�����B�����āA���̂��Ƃ���A�W�b�v�̖@�����p���[�g�̖@�����A�x�L�@���̓��ʂ̏ꍇ�Ƃ������Ƃ��킩��B������A�ΐ��O���t������Ă��̌X���ׂȂ��ƁA�Q�����W���Ƃ����̂͂����Ȃ��B
S�F����Ƃ���Ő��藧����Ƃ����āA�����S�Ă̏ꍇ�ɓ��Ă͂߂�̂͊ԈႢ�Ƃ������ł��ˁB
S�F�ł��A���܂Ō��Ă����f�[�^�́A1�ʂ��_���g�c�ő�����B
T�F���̃T�C�g�����āB���@�y���Ȃ��̋������x�uGlobal Rich List�v�z
S�F�N�Ԏ���������ˁB���[���H�B���͐^�ȏゾ��B����������B
T�F���x�́A�N���P�疜�~�����Ă����B
S�F�قƂ�ǃg�b�v���B�ǂ����āH���E�ɂ͂����Ƌ�����������͂��Ȃ̂ɁB
T�F���̂킯�́A���܂ōl���Ă������Ƃ���킩���BS�F��ɂ͏オ����A���ɂ͉�������Ƃ������Ƃ��B�ł��A�命���̐l�͕n�R���B������x�L�@���݂����B
S�F�������E�������_���Ȃ�A�����ƕ��ω����Ă���悤�Ɏv�����ǁA�ǂ�����1�ʁi�ꕔ�j������Ȃɂ�������W�߂��ł��傤���B
T�F����ɂ��ẮA���̖{���Љ�悤�B�A���o�[�g=���Y���E�o���o�V���y�V�l�b�g���[�N�v�l�`���E�̂����݂�ǂ݉����`�z�Ƃ����{���B
�S�A���E�͂Ȃ����ω����Ă��Ȃ��̂��낤���@���@�y�m�[�h�ƃ����N�ƃN���X�^�[�z
T�F���̖{�ɂ́A�u�l�b�g���[�N�v�́u�����N�v�������ω����Ȃ��ŕ肪����A�������A�x�L�@���ɏ]���̂͂Ȃ����Ƃ������Ƃ��l�@����Ă���B
S�F�l�b�g���[�N���ĉ��H�����N���ĉ��ł����H
T�F���E���A���_�i�m�[�h�j�ƁA������Ȃ��ł�����i�����N�j�łł����O���t�ƍl����B
S�F���E���Ă���ȂɒP���ł͂Ȃ��ł���B
T�F���G�Ȑ��E��ǂ݉������߂ɁA�P�������ă��f�������A�����ɂ��낢��ȏ��������Ȃ��猻���̃l�b�g���[�N�̐��E��T���Ă����Ƃ������@�ȂB
S�F�C���^�[�l�b�g�̃T�C�g��A�l�Ɛl�Ƃ̂Ȃ�����ЂƉ�Ђ̂Ȃ�����l�b�g���[�N���ˁB
S�F���d����ϓd���_�i�m�[�h�j�ɁA���d������i�����N�j�ɂ���l�b�g���[�N���ł���B
S�F�]�זE��_�o����������B�̎}�����āA�삾���āA��ʖԂ����Ă�������B
T�F�Ƃ����悤�ɁA���낢��Ȃ��̂��l�b�g���[�N�Ƃ��ă��f�����ł���B�ŏ��́A���̃l�b�g���[�N�̃����N���A�����_���ł��郂�f������o������B
S�F�����_���Ƃ����̂͂ł���߂Ƃ������Ƃł���B���������]�����Č��߂Ă���Ƃ������Ƃł��ˁB
T�F��������č�����l�b�g���[�N�ł́A�����̃l�b�g���[�N�Ƃ͈Ⴄ�Ƃ������������ɂ킩��B�Ⴆ�A�u���E�̒N�Ƃł��U�l�łȂ����Ă���v�Ƃ����b������B
S�F���E�̒N�Ƃł��A�m�荇�����U�l�ʂ���Ȃ���Ƃ����b�ł���B
T�F�ł��A����̓A�����J�����ōs���������炵���B���ς���ƂU�l���炢�ŁA�莆���`������Ƃ������ʂɂȂ����B���̂Ȃ���̉̂��Ƃ��A���̃l�b�g���[�N�̋����Ƃ����B
S�F���E�ł͂Ȃ��B�ł��A�A�����J�łU�l������A���E�Ȃ�1�W�l���炢�łȂ��肻���B
T�F���́A�͂����莆�̂Ȃ���ω������̂ł����āA�͂��Ȃ������莆�����\�����B
S�F���E���A�������U�l�łȂ����Ă���Ƃ����b�Ȃ烍�}���`�b�N����B
T�F������ɂ��Ă��A�Ȃ��A�������U�l�łȂ����Ă���̂��Ƃ������Ƃ����ƂȂ�B
S�F�P�l�̗F�l��25�l������A�Q�T6���Q�D�S���l�ł��������A�����J�̐l���ɂȂ�B�܂�A�P�l��25�l�m�荇����������A�U�l�ڂŃA�����J�̑S�Ă̐l������A�U�l�łȂ���B
S�F����Ȃ̂���������B�����āA�m�荇���͂����Ă��d�Ȃ��Ă���ꍇ��������B
T�F�����B������A�S�Ă������_���Ɍ�����Ă���Ƃ������f���ɁA�����N�̏d�Ȃ���l������K�v���o�Ă���B �����͗F�������d�Ȃ��Ă���̂ŁA���̏d�Ȃ肮������\������W���i�N���X�^�����O�W���j������B
�����͗F�������d�Ȃ��Ă���̂ŁA���̏d�Ȃ肮������\������W���i�N���X�^�����O�W���j������B
�Ⴆ�A���̗F�l���S�l�Ƃ���B�Ƃ��낪�A���̗F�l�l�b�g���[�N�́A�����N���T�{�����Ȃ������B
S�F���ƗF�����͂Ȃ����Ă��邯�ǁA�F�������m�ł́A�Q�l�����Ȃ����Ă��Ȃ������Ƃ������Ƃł��ˁB
T�F�����B�����A�T�l�����S�ɂȂ��肠���Ă���Ƃ���ƁA�T�i�T-�P�j�^�Q���P�O�{����i���}�j�B�Ƃ��낪�A���ۂ̓����N���T�{�����Ȃ��B���̂Ƃ��A�N���X�^�����O�W��C�́A�T�^�P�O���O�D�T�ŕ\�����B�W�����P�ɂȂ�قnj��т��������Ƃ������ƂɂȂ�B�������ʉ�����A����l�b�g���[�N���m�[�h���m�����Ă���Ƃ���ƁA
�N���X�^�����O�W�����Q�i���ۂ̃����N���j�^�m(�m-1)�@�ŋ��܂�B
S�F�ց[�B���ꎄ�����̃N���X�ɓ��Ă͂߂Čv�Z���邱�Ƃ��ł������B
S�F�N���X���e���ł���A�P�ɋ߂Â��Ƃ������Ƃł��ˁB
T�F���R�A�l�b�g���[�N�������_���ȂقǁA�N���X�^�����O�W���̒l�͏������Ȃ�B
�����ɂ͂��̃N���X�^�����O�W�����ǂꂭ�炢���킩��Ȃ����ǁA���낢��Ȓl��ݒ肵�ă��f���ŃV�~�����[�g���邱�Ƃ��ł���B
�T�A�u�n�u�v�Ɓu�X�P�[���t���[�E�l�b�g���[�N�v
T�F�A�����J�l�̃l�b�g���[�N�͂Q���l������̂ɁA�Ȃ���̋����͒Z���B���������l�b�g���[�N���A�X���[�����[���h(small-world)�Ƃ����B
(1)
�S�����N�����S�m�[�h���̐��{���x�����Ȃ��A���������̃l�b�g���[�N�ł���B
(2)
�ɂ�������炸�A�C�ӂ̓�̃m�[�h�ԋ������m�[�h���ɂ���ׂĒ������Z���B
�@�@�@�i�S�m�[�h�����m�Ƃ���ƁA�m�[�h�ԋ�����log(N)�̃I�[�_�[���x�j
(3)
�܂��A���x�ɃN���X�^�[�����Ă���B
�Ƃ��������������킹�āA�X���[�����[���h�ƌĂԁB
S�F���E�͈ĊO�����Ƃ������Ƃł��ˁB
S�F���������Ďw���̋t���������ˁB�Ӗ��͂��܂�킩��Ȃ����ǁA�p�\�R���̓d��Ōv�Z�ł����B
S�F�������i�Q���j��8.3�����A�������i60���j��9.8����B
S�F���E�́A9.8�łȂ����Ă���Ƃ������ƂȂ̂��B60���l�ł�����Ȃɑ����Ă��Ȃ��B���͂��Ă��Ȃ���B
T�F�m�[�h���̑ΐ��ɔ�Ⴕ�Ă���B�ł��A���ꂼ��̃l�b�g���[�N�ŋ��߂鎮���Ⴄ�B�Ⴆ�A�E�F�u�̃m�[�h�ԋ����́AN�̃E�F�u�y�[�W�����E�F�u��ŁA�m�[�h�Ԃ̕��ϋ��������Ƃ���ƁA
����0.35�{�Q�������m�@�ƂȂ�B
S�F�N���X�^�[���ĉ��ł����H
T�F�N�����̗F�l�̃l�b�g���[�N�̂悤�ȁA���_�i�m�[�h�j���m���ٖ��ɉ�ɂȂ��Ă��邱�ƁB���ɂ����ăN���X�^�[������B�����āA�N���X�^�����O�W���͂��ٖ̋����̓x������\���Ă���B
S�F����ŁA�����ɍ����l�b�g���[�N�͍�邱�Ƃ��ł����́H
T�F�܂��܂��B��������Ē��ׂĂ����ƁA�����̃l�b�g���[�N�ɂ́A�ŏ��̃J�E���g���̂悤�ȁA���ʂɃ����N�̐��̑����m�[�h�����邱�Ƃ��킩���Ă����B���������m�[�h���A�u�n�u�v�i�����N�̔��ɑ傫���m�[�h�̂��ƁA�X�P�[���t���[�E�l�b�g���[�N�ɂ������݂��Ȃ��B)�Ƃ����B
S�F�������ł����ƁA���S�ɂȂ��Ă���l�̂��Ƃ��ˁB
T�F�Ƃ��낪�A�X���[�����[���h�E�l�b�g���[�N�E���f���ł́A�n�u��x�L�@���͌����Ȃ��B
S�F�X�P�[���t���[�Ƃ����͉̂��H
T�F�O�ɂłĂ����悤�ȁA�ׂ����i���z�j�ɂȂ鐫���̂��ƁB
S�F��ɂ͏オ����Ƃ������Ƃ��B�ǂ����ăX�P�[���t���[�Ƃ����́H
T�F�������̃O���t�́A�݂�ȑ����������ł��傤�B���l�ɁA�o�Ȑ��̃O���t�������ɂȂ�B�܂�A�ǂ̕������Ƃ��Ă������`�ɂȂ邩��A���̕������ƌ���ł��Ȃ��B������X�P�[���t���[�Ƃ����B
S�F�܂�x�L���́A�����ɂȂ鐫��������Ƃ������Ƃł��ˁB
T�F�����āA���҂�������������f�����A�X�P�[���t���[�E���f���B�l�b�g���[�N�ɁA�u�����v�Ɓu�D��I�I���v�Ƃ����T�O�����邱�ƂŁA�l�b�g���[�N�̃X�P�[���t���[������ł��邱�Ƃ��������B
S�F�l�b�g���[�N����ɐ������Ă��āA�m�[�h�̃����N�ɗD����Ɖ��肷��A�ׂ��@�����o�Ă���Ƃ������Ƃł��ˁB
S�F���������A�����͂ǂ�ǂ�����邵�A�������ɂ������W�܂郊���N����t���邩��ˁB
T�F�������A���̃��f���́A�C�ӂ̓�̃m�[�h�ԋ������m�[�h���ɂ���ׂĒ������Z���Ƃ��������͎�����A�N���X�^�����O�W���͏������̂ŃX���[�����[���h�̐����͎����Ȃ��炵���B
S�F�����������Ƃ��������ĉ������߂ɂȂ�́H
T�F�ŏ��ɍl�����悤�ɁA���E�̓l�b�g���[�N�ƂƂ炦�邱�Ƃ��ł���ł���B�Ⴆ�A�E�C���X�̍L������A�l�b�g���[�N�łƂ炦�邱�Ƃ��ł���B�R���s���[�^��E�C���X��A�G�C�Y�E�E�C���X�Ȃǂ��ǂ̂悤�Ɋg�U���邩�A�ǂ�����������ł��邩�Ƃ��������ɖ𗧂Ă邱�Ƃ��ł���B
�U�A��c�l�b�g���[�N
T�F�u�V�T�O�N�O�̓��{�̐l���͂P�O���l�I�H�v�Ƃ�����肪����B���̖����A�l�b�g���[�N�̃��f���ōl����Ƃǂ��Ȃ邾�낤���B
S�F�������B�ꑰ���l�b�g���[�N���ˁB�������A��c�̓����N���Q�Ƃ͂����肵�Ă���B
S�F�q�ǂ��͂R�l���炢���ȁB�Ƃ���ƁA���σ����N���͂T���B�e�q�̋����͂P�A�Z�킾�ƂQ����B�v�w�͎q�ǂ���ʂ��ĂQ�B
S�F�ǂ����ŁA�����N�̑����m�[�h�����邵�A�N���X�^�����O�W�������߂Ȃ��ẮB
S�F�ǂ�ǂ����Ă��邩��A�X�P�[���t���[�E�l�b�g���[�N�Ƃ��l������B
S�F�ł��A�����N�̐��͂���Ȃɑ����Ȃ��͂�������A�n�u�͂Ȃ���B�i����ƐĂł��T�T�j
T�F�����A��c�l�b�g���[�N�������_����l�b�g���[�N�Ȃ�A���ϋ������m�[�h���̊��Ƃ��ė\���ł���BN�̃m�[�h������A�e�m�[�h�����ς��{�̃����N�����Ƃ���ƁA�������N�͂Ȃꂽ�m�[�h�́A��d��N���Ă͂����Ȃ��B
���������āA��d��N�B
����āA������kN���������m�^�������������ƂȂ�B
��c�l�b�g���[�N�ł͊e�m�[�h�͂T�̃����N��������A�����T�B�܂��A���Ƃ���30��O��ݒ肷��B
�������m�^�������T���R�O
�������m���R�O�~�O�D�V���Q�P
�ƂȂ�A�m���P000000000000000000000�l�ƂȂ��Ă��܂��B���ꂪ��肾�������ǁA������t�ɍl���Ă݂悤�B
�܂��A�]�ˎ���܂ł̐����Ă����l���̍��v���o���B�{�N�̌v�Z�ɂ��ƁA���ꂪ�ӊO�Ȃ��Ƃ�1���V�疜�l�ȂB
�i���̌v�Z�̂Ƃ��A�Бΐ��O���t���ƂĂ��𗧂����B�j
S�F���܂Ő����Ă����l���ׂĂ��m�[�h�ɂ����A��c�l�b�g���[�N���l���悤�Ƃ����킯�ł��ˁB
T�F�����ł��B���̌v�Z���������Ƃ��āA�]�ˎ���܂ł̎q���l�b�g���[�N���l����ƁA
�����������i1.7�~�P�O8�j�^�������T���P�Q�ƂȂ�B
S�F����́A�]�ˎ���܂ł̓��{�̑S�Ă̐l�ƁA���ςP�Q�����N�łȂ����Ă���Ƃ������Ƃł͂Ȃ��́B
S�F��c���ꏏ�������肵�āA�����̂ڂ��ĉ�����Ƃ������Ƃ������ˁB
S�F�ł��A���ꂾ�Ǝ��オ����Ή���قǁA�������������Ȃ��Ă���������B
T�F�������ˁB������A�킩���Ă��邱�Ƃ������āA��e��ʂ��ē��{�l�͂X�̉ƌn�ɕ������Ƃ����B��������ƁA�ޗǎ���܂ł����̂ڂ�A�����Ă����l�̑����v���A�قڂQ���l�Ƃ��āA������X�ł��ƁA�Q�疜�l�B����Ōv�Z����ƁA����10.4����B
S�F�X�Ƒ��̈�����Ƃ���A���ϋ����͂P�O�Ƃ������ƂȂ�ł��ˁB�ق�Ƃ��ȁB
S�F�X�Ƒ��Ƃ���������������B�X�l�ɂP�l�͂Ȃ����Ă���Ƃ������Ƃ̕����B
T�F������ɂ��Ă��A���̐�c�l�b�g���[�N���A�O���t���_�ł����ƒ��ׂȂ�������B
S�F���낢��ʔ������B�܂��A�������Ă݂܂��傤�B
�Q�l�����@�y�V�l�b�g���[�N�v�l�`���E�̂����݂�ǂ݉����`�z�A���o�[�g=���Y���E�o���o�V��
�ڎ��ւ��ǂ�